Jose Vidal
Agent
(Licensed as Jose Vidal Cadena)
License: California DRE #02014729
Jose Vidal understands that real estate is more than just a transaction; it's a life-changing experience. As a dedicated real estate agent serving the neighborhoods of Sherman Oaks, Encino, Tarzana, Woodland Hills, and Calabasas, Jose offers intimate local knowledge and tailored services throughout the San Fernando Valley area.
Born and raised in the San Fernando Valley, Jose brings an insider’s perspective to the various neighborhoods of LA County. He graduated from California State University Northridge with a major in Business Management, which complements his Associate’s Degree in Social and Behavioral Science. This academic background provides him with a keen understanding of both the business and human sides of real estate, a combination that he leverages to serve his clients in a holistic way.
Jose employs the latest technology to keep abreast of the ever-changing market conditions and trends. He is committed to continual learning, staying updated on current legislation and market strategies, which empowers his clients with up-to-date information and data-driven insights.
What sets Jose apart is his approach. He deeply values the relationships he builds with his clients and strives to empower them with the knowledge and resources they need to make confident, informed decisions. Whether you’re a first-time homebuyer, looking to sell your property, or an investor seeking new opportunities, Jose is there to guide you every step of the way.
In his free time, Jose is a passionate car enthusiast. He loves attending local car shows, reflecting his appreciation for design and craftsmanship, which he also applies when considering properties. He understands that a home, like a cherished car, is more than just an asset—it's a lifestyle and a part of one's identity.
With Jose Vidal, you’re not just getting a real estate agent; you’re gaining a dedicated partner who will stand by your side, ensuring your experience is seamless, rewarding, and tailored to your individual goals.
Born and raised in the San Fernando Valley, Jose brings an insider’s perspective to the various neighborhoods of LA County. He graduated from California State University Northridge with a major in Business Management, which complements his Associate’s Degree in Social and Behavioral Science. This academic background provides him with a keen understanding of both the business and human sides of real estate, a combination that he leverages to serve his clients in a holistic way.
Jose employs the latest technology to keep abreast of the ever-changing market conditions and trends. He is committed to continual learning, staying updated on current legislation and market strategies, which empowers his clients with up-to-date information and data-driven insights.
What sets Jose apart is his approach. He deeply values the relationships he builds with his clients and strives to empower them with the knowledge and resources they need to make confident, informed decisions. Whether you’re a first-time homebuyer, looking to sell your property, or an investor seeking new opportunities, Jose is there to guide you every step of the way.
In his free time, Jose is a passionate car enthusiast. He loves attending local car shows, reflecting his appreciation for design and craftsmanship, which he also applies when considering properties. He understands that a home, like a cherished car, is more than just an asset—it's a lifestyle and a part of one's identity.
With Jose Vidal, you’re not just getting a real estate agent; you’re gaining a dedicated partner who will stand by your side, ensuring your experience is seamless, rewarding, and tailored to your individual goals.

Properties Listed by Jose




















Listing courtesy of The Agency












Listing courtesy of The Agency





































Listing courtesy of The Agency

























































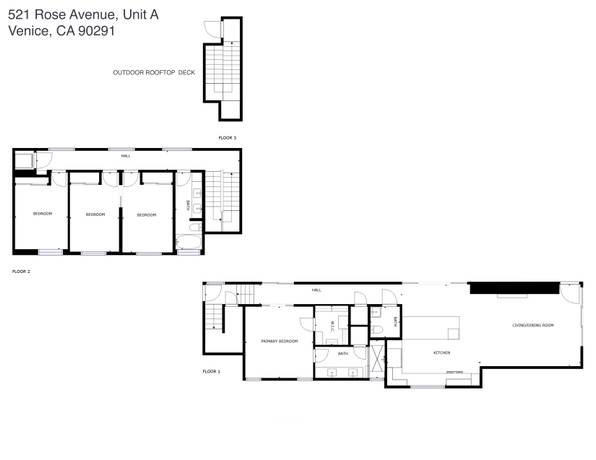
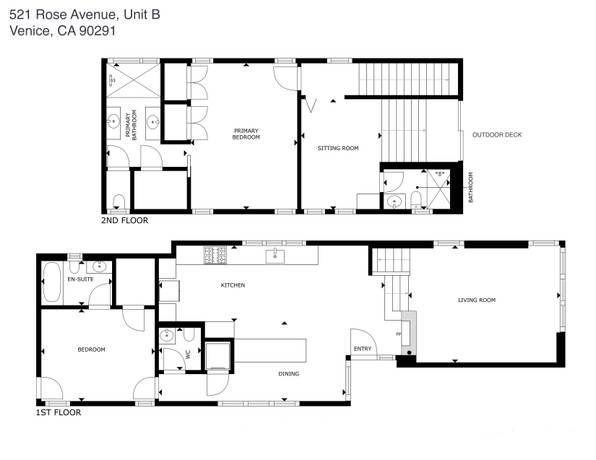
Listing courtesy of The Agency

























































Listing courtesy of The Agency
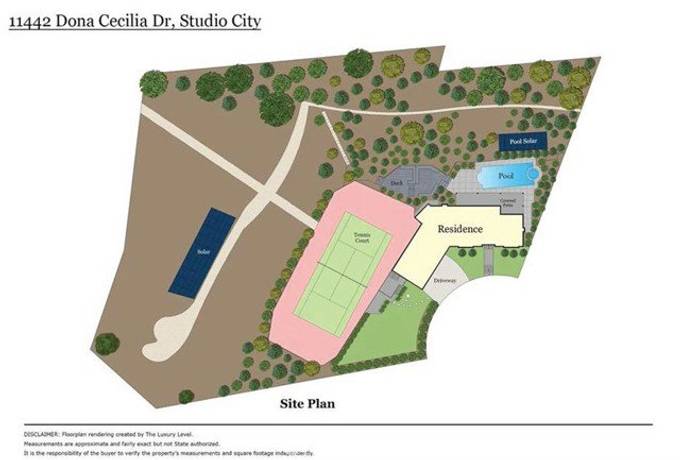
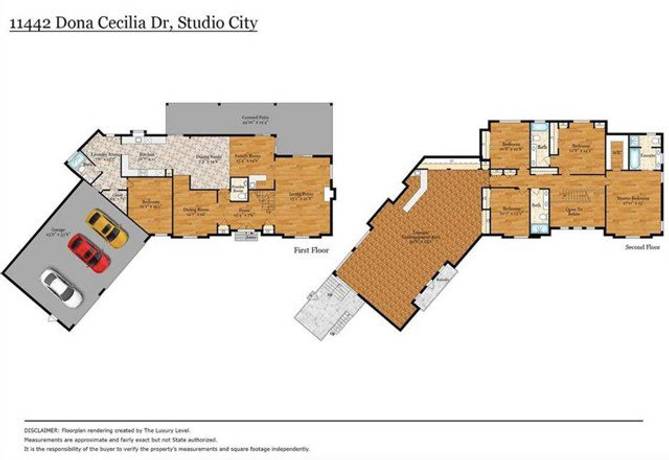
in contract
Listing courtesy of The Agency

in contract
Listing courtesy of The Agency














































Listing courtesy of The Agency








































Open House
Apr 23, 11:00 AM – 2:00 PM
Apr 26, 11:00 AM – 2:00 PM
Listing courtesy of The Agency











Listing courtesy of The Agency



































































Listing courtesy of The Agency







































Open House
Apr 27, 1:00 – 4:00 PM
Apr 28, 1:00 – 4:00 PM
Listing courtesy of The Agency
Featured Past Transactions by Jose
closed
Represented the buyer
































closed
Represented the seller














closed
Represented the seller
closed
Represented the buyer